Табличные пространства, слои и длинные версии строк#
Табличные пространства#
Табличные пространства (ТП) служат для организации физического хранения данных и определяют расположение данных в файловой системе.
Табличные пространства в PostgreSQL позволяют администраторам организовать логику размещения файлов объектов базы данных в файловой системе. К однажды созданному табличному пространству можно обращаться по имени на этапе создания объектов.
Табличные пространства позволяют администратору управлять дисковым пространством для инсталляции PostgreSQL:
1. При нехватке места в разделе, на котором был инициализирован кластер и невозможность его расширения табличное пространство можно создать в другом разделе и использовать его до тех пор, пока не появится возможность переконфигурирования системы.
2. Табличные пространства позволяют администраторам оптимизировать производительность согласно бизнес-процессам, связанным с объектами базы данных. Например, часто используемый индекс можно разместить на очень быстром и надёжном, но дорогом SSD-диске. В то же время таблица с архивными данными, которые редко используются и скорость к доступа к ним не важна, может быть размещена в более дешёвом и медленном хранилище.
При инициализации кластера создаются два ТП: pg_default и pg_global.
Заметим, что у каждой базы данных есть табличное пространство по умолчанию, им является pg_default. Это то табличное пространство, в котором, если не указать иное явно, будут создаваться все объекты базы. В этом же табличном пространстве по умолчанию база данных хранит свой системный каталог. Табличное просторанство pg_global предназначено для хранения объектов системного каталога, содержащего информацию об объектах уровня всего всего кластера.

На картинке видно, что различные базы данных могут хранить свои объекты в разных табличных пространствах, а в одном табличном пространстве мы получаем объекты разных баз данных.
Таким образом, логическая и физическая организация данных являются независимыми между собой.
По сути, табличное пространство это ссылка на некий каталог, где располагаются файлы с данными.
Для табличных пространств pg_default и pg_global местоположение фиксировано. pg_global располагается в каталоге PGDATA/global. Табличное пространство pg_defaul соответствует подкаталогу PGDATA/base
Внутри каталога PGDATA/base/ данные дополнительно разложены по подкаталогам баз данных, имеющих цифровые названия, они совпадают с идентификаторами баз данных. Таким образом, объекты разных баз данных лежат в pg_defaul разложенные по соответствующим каталогам соответствующих баз данных. (для PGDATA/global/ это не требуется, так как данные в нем относятся к кластеру в целом)
Для создания табличного пространства используется команда CREATE TABLESPACE, например:
::
CREATE TABLESPACE fastspace LOCATION ‘/ssd1/postgresql/data’;
Important
Каталог должен существовать, быть пустым и принадлежать пользователю ОС, под которым запущен PostgreSQL.
Все созданные впоследствии объекты, принадлежащие целевому табличному пространству, будут храниться в файлах расположенных в этом каталоге.
Warning
Каталог не должен размещаться на съёмных или устройствах временного хранения, так как кластер может перестать функционировать из-за потери этого пространства.
Создавать табличное пространство должен суперпользователь базы данных, но после этого можно разрешить обычным пользователям его использовать. Для этого необходимо предоставить привилегию CREATE на табличное пространство.
Таблицы, индексы и целые базы данных могут храниться в отдельных табличных пространствах. Для этого пользователь с правом CREATE на табличное пространство должен указать его имя в качестве параметра соответствующей команды. Например, далее создаётся таблица в табличном пространстве space1:
CREATE TABLE foo(i int) TABLESPACE space1;
Для установки табличного пространства по-умолчанию :
SET default_tablespace = space1;
или для базы данных:
ALTER DATABASE <database> SET TABLESPACE ts;
При создании пользовательского ТП указывается произвольный каталог; для собственного удобства PostgreSQL создает на него символическую ссылку в каталоге PGDATA/pg_tblspc/. Эта символьная ссылка получает имя по OID табличного пространства.
Внутри каталога пользовательского ТП появляется еще один уровень вложенности: версия сервера PostgreSQL, например PG_16_202307071 Это сделано для удобства обновления сервера на другую версию. Внутри каталога конкретной версии находится подкаталог для каждой базы данных, которая имеет элементы в табличном пространстве, названный по OID базы данных. Таблицы и индексы хранятся внутри этого каталога, используя схему именования файловых узлов.
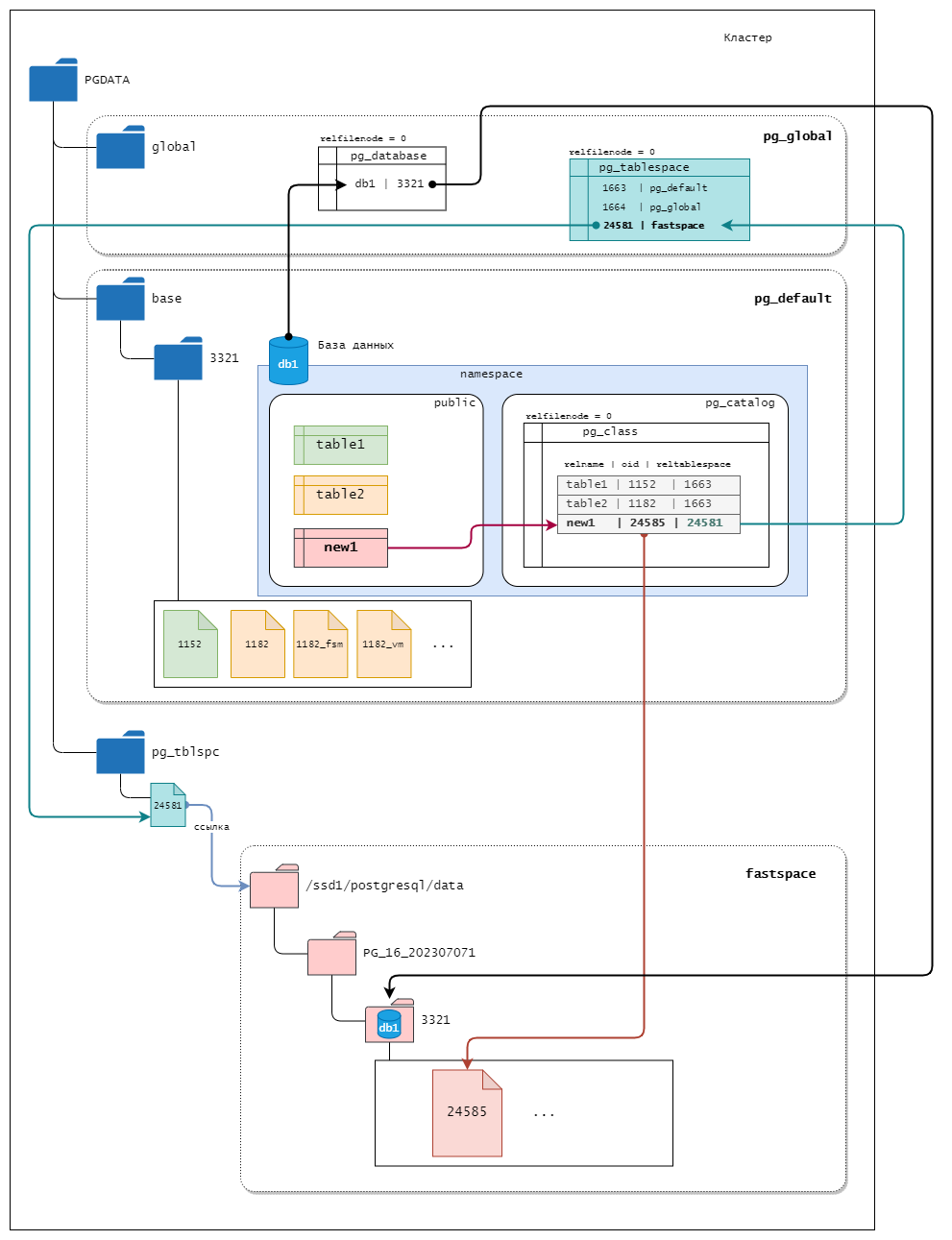
Табличное пространство pg_default недоступно через pg_tblspc, но соответствует PGDATA/base. Табличное пространство pg_global недоступно через pg_tblspc, но соответствует PGDATA/global.
Практика:#
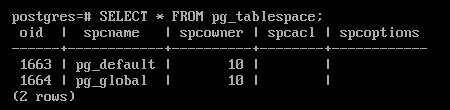
Получить список имеющихся табличных пространств:
SELECT * FROM pg_tablespace;
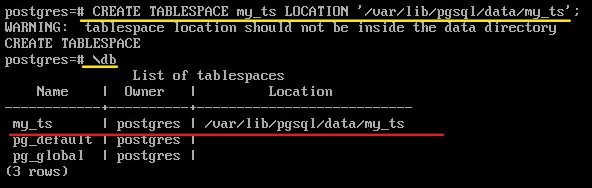
Создать пользовательскоe табличное пространство:
sudo -u postgres mkdir /var/lib/pgsql/data/my_ts
Подключиться к postgres и создать табличное пространство:
CREATE TABLESPACE my_ts LOCATION '/var/lib/pgsql/data/my_ts';
\db
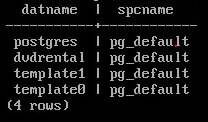
Вывести для имеющихся баз в кластере табличное пространство “по умолчанию”:
SELECT a.datname, b.spcname FROM pg_database a INNER JOIN pg_tablespace b ON
a.dattablespace = b.oid;

Создадим базу appdb и назначим ей my_ts в качестве табличного пространства по-умолчанию:
CREATE DATABASE appdb TABLESPACE my_ts;
Вывести для имеющихся баз в кластере табличное пространство “по умолчанию”:
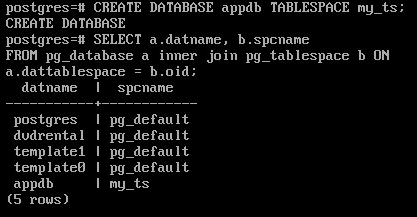
Теперь все создаваемые таблицы и индексы будут попадать в my_ts, если явно не указать другое.
Подключиться к базе appdb:
\c appdb
Создать таблицу:
CREATE TABLE t1(
id integer GENERATED ALWAYS AS IDENTITY,
name text
);
Будет создана в ТП my_ts
Создать вторую таблицу в прострастве pg_default:
CREATE TABLE t2(
n numeric
) TABLESPACE pg_default;

Пустое поле tablespace указывает на табличное пространство по умолчанию, а у второй таблицы поле заполнено.
Создать индекс для t1 в pg_default
CREATE INDEX ON t1(id) TABLESPACE pg_default;
SELECT * FROM pg_indexes WHERE tablename='t1' \gx
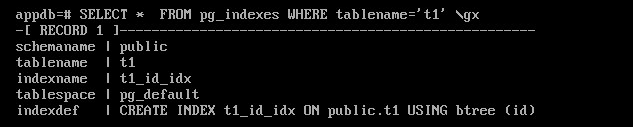
Таблица в одном ТП, а индекс - в другом.
Создать новую базу данных и подключиться к ней:
CREATE DATABASE configdb;
Табличным пространством по умолчанию для данной базы данных будет pg_default.
\c configdb
Создать таблицу t в табличном пространстве my_ts:
CREATE TABLE t(
n integer
) TABLESPACE my_ts;
\d t
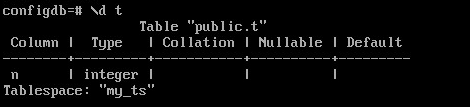
Для временных таблиц и их индексов можно указать отдельное табличное пространство по умолчанию:
SET temp_tablespaces = 'my_ts';
CREATE TEMP TABLE temp(s text);
\d temp
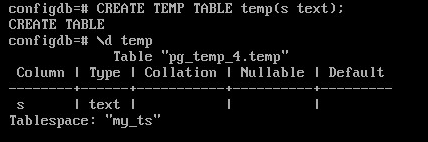
В параметре temp_tablespaces можно указать несколько табличных пространств, в этом случае сервер выберет одно из них случайным образом.
Управление объектами в табличных пространствах#
Таблицы (и другие объекты, например, индексы), можно перемещать между табличными пространствами. Это физическое перемещение файлов данных из одного каталога в другой. На время ее выполнения доступ к перемещаемому объекту полностью блокируется.
\c appdb
Переметить таблицк t1 в ТП pg_default:
ALTER TABLE t1 SET TABLESPACE pg_default;
SELECT tablename, tablespace FROM pg_tables WHERE schemaname = 'public';

Перенести индексы можно и при перестроении:
REINDEX (TABLESPACE ts) TABLE t1;
Переместить все объекты из pg_default в my_ts:
ALTER TABLE ALL IN TABLESPACE pg_default SET TABLESPACE my_ts;

Размер табличного пространства#
Вычисляется аналогично размеру базы данных:
SELECT pg_size_pretty( pg_tablespace_size('my_ts') );

Размер табличного просторанства my_ts обусловлен наличием в нем таблиц системного каталога, по причине того, что оно установлено по умолчанию.
Удаление табличного пространства#
Удалить можно только пустое ТП.
Синтаксис:
DROP TABLESPACE <name_tblspc>;
DROP TABLESPACE my_ts;
Удаление не выполнено, так как ТП содержит объекты, причем принадлещие разным базам данных.
С помощью системного каталога получим перечень баз данных, использующих это ТП:
SELECT oid FROM pg_tablespace WHERE spcname = 'my_ts';

SELECT datname
FROM pg_database
WHERE oid IN (SELECT pg_tablespace_databases(16772));
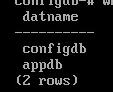
\c configdb
SELECT relnamespace::regnamespace, relname, relkind
FROM pg_class
WHERE reltablespace = 16772;
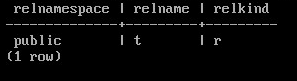
DROP TABLE t;
В базе appdb my_ts установлено по умолчанию. ПО этой причине идентификатор ТП будет равен 0. И все таблицы системного каталога находятся в этом пространстве. Необходимо перенести все эти объекты в табличное пропростраство pg_default, а потом удалить my_ts.
\c postgres
ALTER DATABASE appdb SET TABLESPACE pg_default;
DROP TABLESPACE my_ts;
Практическая работа:#
Создайте новое табличное пространство.
Измените табличное пространство по умолчанию для базы данных template1 на созданное пространство.
Создайте новую базу данных. Проверьте, какое табличное пространство по умолчанию установлено для новой базы данных.
Посмотрите в файловой системе символьную ссылку в PGDATA на каталог табличного пространства.
Удалите созданное табличное пространство
Ознакомиться с назначением параметров seq_page_cost и random_page_cost
https://postgrespro.ru/docs/postgresql/current/runtime-config-query
Установить параметр random_page_cost в значение 1.1для табличного пространства pg_default.
Слои#
Объекты базы данных физически хранятся в файлах каталогов, которые определены как табличные пространства. Но представлены они не одним файлом, а целым набором. Обычно каждому объекту БД, хранящему данные (таблице, индексу, последовательности, материализованному представлению), соответствует несколько слоев (forks). Каждый слой содержит определенный вид данных
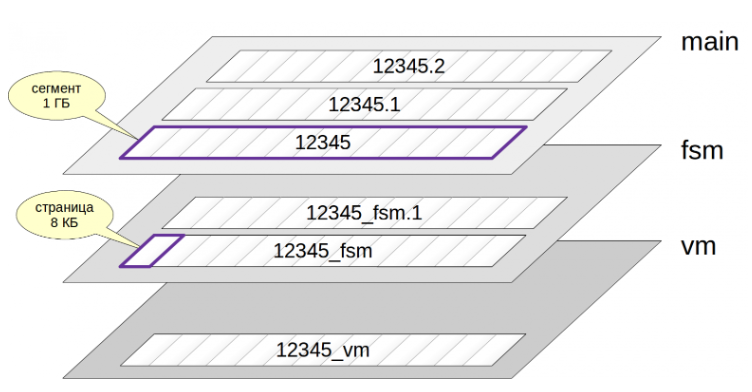
Если слой есть, то вначале он представлен одним-единственным файлом. Имя файла состоит из числового идентификатора, к которому может быть добавлено окончание, соответствующее имени слоя. Общий размер любого слоя показывает функция pg_relation_size
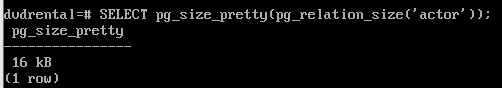
Файл постепенно растет и, когда его размер доходит до 1 ГБ, создается следующий файл - сегмент, этого же слоя. Порядковый номер сегмента добавляется в конец имени файла.
Ограничение размера сегмента в 1 ГБ возникло исторически для поддержки различных файловых систем, некоторые из которых не умеют работать с файлами большого размера. Ограничение можно изменить при сборке PostgreSQL (./configure –with-segsize). Каждый файл, в свою очередь, разделен на страницы (или блоки), обычно по 8 КБ.
Основной слой - это непосредственно данные: версии строк таблиц или индексные записи. Имена файлов основного слоя совпадают с идентификатором. Основной слой существует для любых объектов.
SELECT pg_relation_filepath('actor');
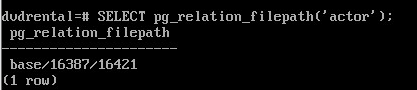
Каталог base соответствует табличному пространству pg_default, следующий подкаталог — базе данных, и уже в нем находится файл отношения:
Функция pg_relation_filepath удобна тем, что выдает готовый путь без необходимости выполнять несколько запросов к системному каталогу.
SELECT oid FROM pg_database WHERE datname = 'dvdrental';

SELECT relfilenode FROM pg_class WHERE relname = 'actor';
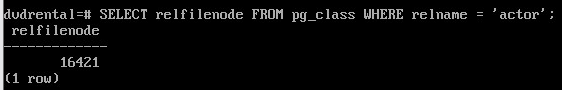
Практически все пути в PostgreSQL отсчитываются относительно PGDATA. По этой причине данный каталог можно переносить на другое место без влияние на то, как POstgres будет находить данные.
Имена файлов слоя инициализации оканчиваются на «_init». Этот слой существует только для нежурналируемых таблиц (созданныхс указанием UNLOGGED) и их индексов. Такие объекты ничем не отличаются от обычных, но действия с ними не записываются в журнал упреждающей записи. За счет этого работа с ними происходит быстрее, но в случае сбоя их содержимое невозможно восстановить. При восстановлении PostgreSQL просто удаляет все слои таких объектов и записывает слой инициализации на место основного слоя. В результате получается пустая таблица.
Оканчивается на _init
Используется только для нежурналируемых таблиц (созданных с указанием UNLOGGED) и их индексов. Такие объекты ничем не отличаются от обычных, но действия с ними не записываются в журнал упреждающей записи. За счет этого работа с ними происходит быстрее, но в случае сбоя их содержимое невозможно восстановить. При восстановлении PostgreSQL просто удаляет все слои таких объектов и записывает слой инициализации на место основного слоя. Файл этого слоя представляет собой пустую таблицу или индекс соответствующего типа. Когда нежурналируемая таблица должна быть заново очищена по причине сбоя, файл инициализации копируется поверх главного файла, а все прочие файлы удаляются (при необходимости они будут автоматически созданы заново).
CREATE UNLOGGED TABLE test (a text);
INSERT INTO test VALUES ('TEST TABLE');
SELECT relfilenode FROM pg_class WHERE relname = 'test';
16827

Слой инициализации имеет такое же имя, как и основной слой, но с суффиксом “_init”.
https://postgrespro.ru/docs/postgresql/16/storage-fsm
Слой, в котором отмечено наличие пустого места внутри страниц. Существует и для таблиц, и для индексов. Это место постоянно меняется: при добавлении новых версий строк уменьшается, при очистке — увеличивается. Карта свободного пространства используется при вставке новых версий строк, для поиска подходящей страницы, на которую запишутся добавляемые данные.
Карта свободного пространства имеет суффикс “_fsm”. Но файл появляется не сразу, а только при необходимости. Самый простой способ добиться этого — выполнить очистку таблицы:

VACUUM actor;

Битовая карта видимости. Имена файлов этого слоя оканчиваются на «_vm». Слой существует только для таблиц; для индексов не поддерживается отдельная версионность. Слой, в котором одним битом отмечены страницы, которые содержат только актуальные версии строк, что означает возможность показать строку без проверки видимости когда транзакция пытается прочитать строку из такой страницы.
Для временных таблиц все работает точно также, но для имени добавляется префикс с номером схемы (t4):
SELECT pg_relation_filepath('t');
pg_relation_filepath
----------------------
base/16387/t4_16839
Утилита oid2name позволяеть сопоставить имена таблиц и имена файлов
sudo -u postgres /usr/bin/oid2name -d dvdrental -t actor
Filenode Table Name
----------------------
16421 actor
sudo -u postgres /usr/bin/oid2name -d dvdrental -f 16421
Filenode Table Name
----------------------
16421 actor
Размер слоев#
Размер файлов, входящих в слой, можно, конечно, посмотреть в файловой системе, но существует специальная функция для получения размера каждого слоя в отдельности:
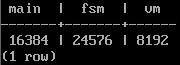
SELECT pg_relation_size('actor','main') main,
pg_relation_size('actor','fsm') fsm,
pg_relation_size('actor','vm') vm;
Страницы#
Файлы логически поделены на страницы.
Обычно страница имеет размер 8 КБ. Размер в некоторых пределах можно поменять (16 КБ или 32 КБ), но только при сборке (./configure –with-blocksize). Собранный и запущенный экземпляр может работать со страницами только одного размера.
SHOW block_size;
Независимо от того, к какому слою принадлежат файлы, они используются сервером примерно одинаково. Страницы сначала читаются в буферный кеш, где их могут читать и изменять процессы; затем при необходимости страницы вытесняются обратно на диск.
Каждая страница имеет внутреннюю разметку и в общем случае содержит следующие разделы:

Для исследования страницы с цель отладки баз данных на низком уровне используется модуль pageinspect:
CREATE EXTENSION pageinspect;
SELECT lower, upper, special, pagesize FROM page_header(get_raw_page('actor',0));

В данном примере рассматривается заголовок самой первой (нулевой) страницы таблицы. Кроме размеров остальных областей заголовок содержит и другую информацию о странице.
В старших адресах (внизу картинки) страницы расположена специальная область, в нашем случае пустая. Она используется только для индексов, и то не для всех. Заполнение страницы данными осуществляется снизу-вверх.
Следом за специальной областью (выше по картинке) располагаются версии строк — те самые данные, которые хранятся в таблице, плюс некоторая служебная информация.
Вверху страницы, сразу за заголовком, находится оглавление: массив указателей на имеющиеся в странице версии строк.
Между версиями строк и указателями может оставаться свободное место (которое и отмечено в карте свободного пространства). Фрагментации внутри страницы не бывает, все свободное место всегда представлено одним фрагментом.
Индексные строки индексных файлов должны ссылаться на версии строк в таблице. Индекс ссылается на номер указателя, а указатель — на текущую позицию версии строки в странице. Получается косвенная адресация.
Каждый указатель занимает ровно 4 байта и содержит:
ссылку на версию строки;
длину этой версии строки;
несколько бит, определяющих статус версии строки.
Каждая версия строки должна помещаться целиком на одну страницу: в PostgreSQL не предусмотрено способа “продолжить” строку на следующей странице. А строчка может быть длинной там могут быть некие атрибуты, содержащие достаточно большие значения. Для этого используется технология, названная TOAST (The Oversized Attributes Storage Technique), то есть строка может нарезаться на тосты.
Этот механизм поддерживает определенные стратегии:
“Длинные” значения атрибутов можно отправить в отдельную служебную таблицу, предварительно нарезав на небольшие фрагменты-тосты.
Другой вариант — сжать значение так, чтобы версия строки все-таки поместилась на обычную табличную страницу.
А можно и то, и другое: сначала сжать, а уже потом нарезать и отправить.
Для каждой основной таблицы при необходимости создается отдельная, но одна для всех атрибутов, TOAST-таблица (и к ней специальный индекс). Необходимость определяется наличием в таблице потенциально длинных атрибутов. Например, если в таблице есть столбец типа numeric или text, TOAST-таблица будет сразу же создана, даже если длинные значения не будут использоваться.
TOAST-таблица - это обычная таблица и нее имеется тот же набор слоев, что еще в два раза увеличивает число файлов, которые «обслуживают» таблицу. Такие таблицы и индексы располагаются в отдельной схеме pg_toast и поэтому обычно не видны (для временных таблиц используется схема pg_toast_temp_N аналогично обычной pg_temp_N).
Изначально стратегии определяются типами данных столбцов. Посмотреть их можно командой d+ в psql:
\d+ actor;
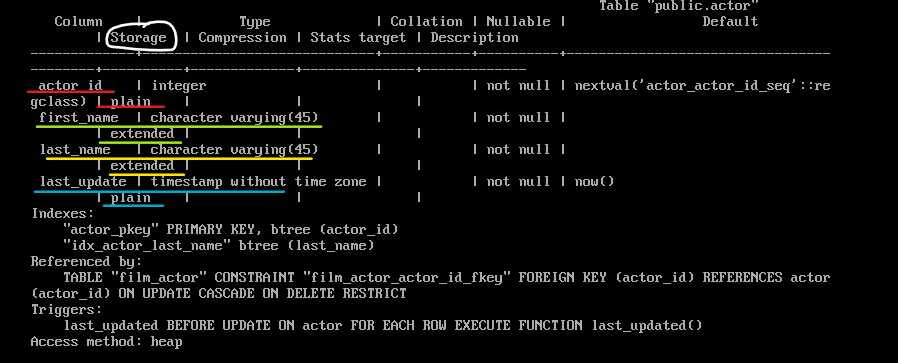
Cтратегии:
plain — TOAST не используется (применяется для заведомо “коротких” типов данных, как integer);
extended — допускается как сжатие, так и хранение в отдельной TOAST-таблице;
external — длинные значения хранятся в TOAST-таблице несжатыми;
main — длинные значения в первую очередь сжимаются, а в TOAST-таблицу попадают только если сжатие не помогло.
Алгоритм выглядит следующим образом:
PostgreSQL стремится к тому, чтобы на странице помещалось хотя бы 4 строки. Поэтому если размер строки превышает четвертую часть страницы с учетом заголовка (при обычной 8К-странице это 2040 байт), к части значений необходимо применить TOAST.
Действия выполняются в следующем порядке и прекращаются, как только строка перестает превышать порог:
Сначала перебираются атрибуты со стратегиями external и extended, двигаясь от самых длинных к более коротким.
При наличии эффекта Extended-атрибуты сжимаются и, если значение само по себе превосходит четверть страницы, то сразу же отправляется в TOAST-таблицу. External-атрибуты обрабатываются так же, но не сжимаются.
Если после первого прохода версия строки все еще не помещается, в TOAST-таблицу отправляются оставшиеся атрибуты со стратегиями external и extended.
Если и это не помогло, осуществляется попытка сжать атрибуты со стратегией main, оставляя их при этом в табличной странице.
И только если после этого строка все равно недостаточно коротка, main-атрибуты отправляются в TOAST-таблицу.
Практика:
Создать в БД postgres таблицу test:
\c postgres
CREATE TABLE test (s text);
Проверить размер таблицы:
SELECT pg_relation_size('test', 'main');
Проверить стртегию хранения данных:
\d+ test
Storage: extended
Проверить наличие toast-таблицы:
SELECT relnamespace::regnamespace, relname
FROM pg_class WHERE oid = (
SELECT reltoastrelid FROM pg_class WHERE relname = 'test'
);
Вставить строку и проверить размер:
INSERT INTO test VALUES('TEST TABLE');
SELECT pg_relation_size('test', 'main');
РАзмер соответствует одной странице - 8Кб.
Вставить строку и проверить размер:
INSERT INTO test VALUES(repeat('A',3000));
SELECT pg_relation_size('test', 'main');
Размер остался тот же, так как повторяющиеся символы хорошо сжимаются.
Вставить строку из 3000 случайных символов и проверить размер:
INSERT INTO test SELECT string_agg( chr(trunc(65+random()*26)::integer), '') FROM generate_series(1,3000);
SELECT pg_relation_size('test', 'main');
Несмотря на добавление 3000 символов размер не изменился. Данные отправлены в toast-таблицу:
SELECT chunk_id,
chunk_seq,
length(chunk_data),
left(encode(chunk_data,'escape')::text, 10) ||
'...' ||
right(encode(chunk_data,'escape')::text, 10)
FROM pg_toast.pg_toast_16878;

Вынесенные в TOAST поля делятся на части - “чанки” (после сжатия, если оно применялось) размером 1996 байт (значение задано константой TOAST_MAX_CHUNK_SIZE), которые располагаются в строках TOAST-таблицы размером 2032 байта (значение задано константой TOAST_TUPLE_THRESHOLD). Значения выбраны так, чтобы в блок таблицы TOAST поместилось четыре строки. Так как размер поля таблицы не кратен 1996 байт, то последний чанк поля может быть меньшего размера.
chunk_id (тип OID, уникальный для поля вынесенного в TOAST размер 4 байта),
chunk_seq (порядковый номер чанка, размер 4 байта),
chunk_data (данные поля, тип bytea, размер сырых данных плюс 1 или 4 байта на хранение размера).
Для быстрого доступа к чанкам на TOAST-таблицу создается составной уникальный индекс по chunk_id и chunk_seq. В блоке таблицы остаётся указатель на первый чанк поля и другие данные.
Как видно, данные нарезаются на фрагменты по 1996 байт.
При необходимости стратегию можно впоследствии изменить. Например, если известно, что в столбце хранятся уже сжатые данные, разумно поставить стратегию external.
ALTER TABLE t ALTER COLUMN n SET STORAGE external;
Эта операция не меняет существующие данные в таблице, но определяет стратегию работы с новыми версиями строк.
При обращении к “длинному” значению PostgreSQL автоматически, прозрачно для приложения, восстанавливает исходное значение и возвращает его клиенту.
Разумеется, и на сжатие с нарезкой, и на последующее восстановление тратится довольно много ресурсов. Поэтому хранить объемные данные в PostgreSQL — не лучшая идея, особенно если они активно используются и при этом для них не требуется транзакционная логика (как пример: отсканированные оригиналы бухгалтерских документов). Более выгодной альтернативой может оказаться хранение таких данных на файловой системе, а в СУБД — имен соответствующих файлов.
Toast-таблица используется только при обращении к длинному значению. Кроме того, для toast-таблицы поддерживается своя версионность: если обновление данных не затрагивает «длинное» значение, новая версия строки будет ссылаться на то же самое значение в toast-таблице — это экономит место.
Дополнительно:
https://habr.com/ru/articles/888926/
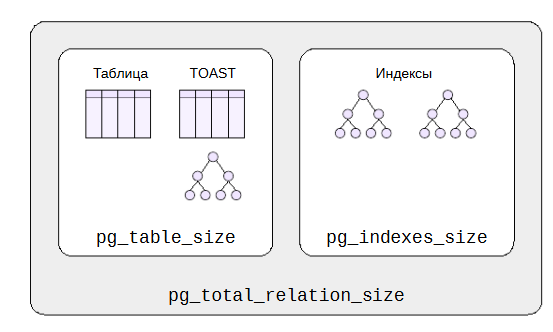
Чтобы не суммировать размеры отдельных слоев, есть несколько функций, показывающих размеры таблицы: - pg_table_size показывает размер таблицы и ее toast-части (toast-таблицы и обслуживающего ее индекса), но без обычных индексов. Эту же функцию можно использовать для вычисления размера отдельного индекса: и таблицы, и индексы являются отношениями,и, несмотря на название, функция принимает любое отношение.
pg_indexes_size суммирует размеры всех индексов таблицы, кроме индекса toast-таблицы.
pg_total_relation_size показывает полный размер таблицы, вместесо всеми ее индексами.
Практика:
Подключиться к бд dvdrental:
\c dvdrental
Размер таблицы, включая toast-таблицу и обслуживающий ее индекс:
SELECT pg_table_size('actor');
Общий размер всех индексов таблицы:
SELECT pg_indexes_size('actor');
Для получения размера отдельного индекса можно воспользоваться функцией pg_table_size. Toast-части у индексов нет, поэтому функция покажет только размер всех слоев индекса (main, fsm).
Сейчас у таблицы есть только индекс по первичному ключу, поэтому размер этого индекса совпадает со значением pg_indexes_size:
SELECT pg_table_size('actor_pkey') AS actor_pkey;
Общий размер таблицы, включающий TOAST и все индексы:
SELECT pg_total_relation_size('actor');
Самостоятельно:#
1. Создайте нежурналируемую таблицу в пользовательском табличном пространстве и убедитесь, что для таблицы существует слой init. Удалите созданное табличное пространство.
2. Создайте таблицу со столбцом типа text.Какая стратегия хранения применяется для этого столбца? Измените стратегию на external и вставьте в таблицу короткую и длинную строки. Проверьте, попали ли строки в toast-таблицу, выполнив прямой запрос к ней. Объясните, почему.